Function Form
The following benchmarks test the conversion of the entire set of valid Unicode Scalar Values (all Unicode code points, except the surrogate values used for UTF-16). The transcoding done is UTF-32 to UTF-8, with as-identical an internal conversion routine as possible. The only differences in the internal workings of the conversion are in reaction to the inputs and outputs given.
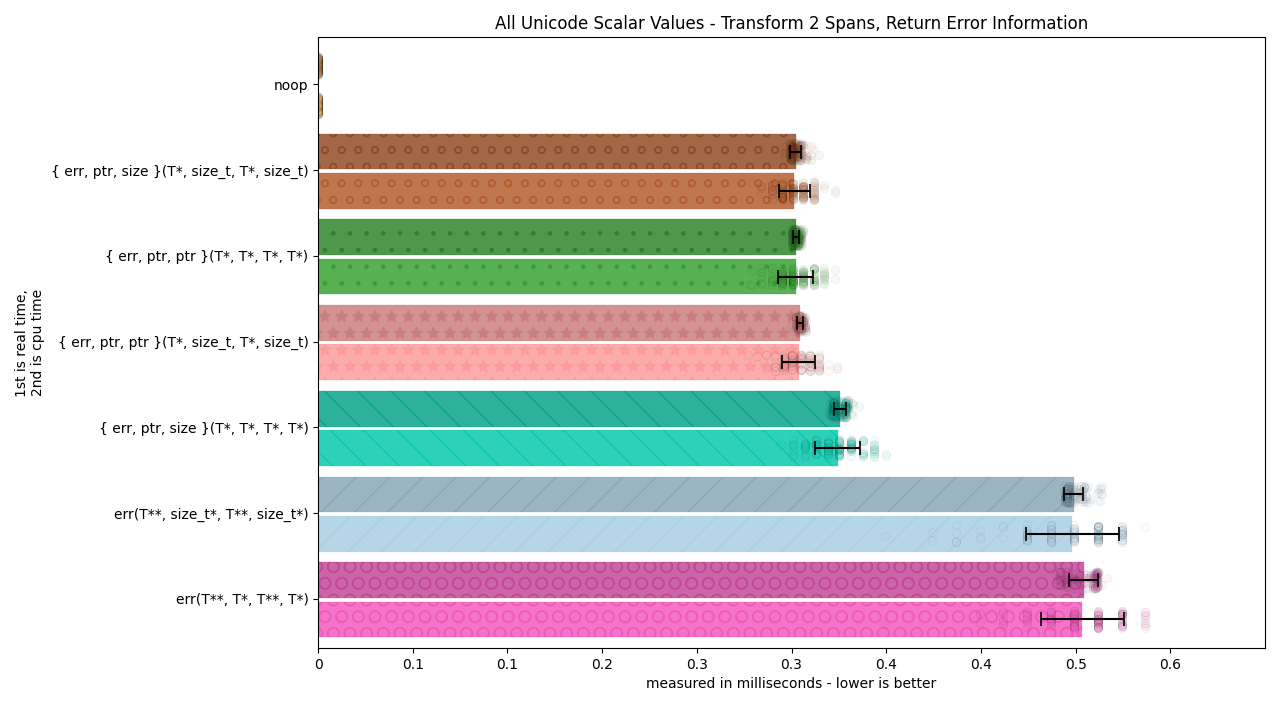
The goal of these benchmarks is to measure how using a basic, single (indivisible unit of work) conversion run in a loop can affect speed based on how the function is structured. This is mostly relevant in the case of libraries like musl-libc, where the maintainers expressly declared they would NOT optimize the bulk-conversion functions to do anything and would rather write the base conversion loop:
…
On musl (where I’m familiar with performance properties), byte-at-a-time conversion is roughly half the speed of bulk, which looks big but is diminishingly so if you’re actually doing something with the result (just converting to wchar_t for its own sake is not very useful).
—Rich Felker, December 30th, 2019, musl libc mailing list.
Here, we can see how writing the bulk conversion functions in terms of the single functions are affected by a given API design.
All Unicode Code Points
C Basic Source Character Set