First Principles - “Lucky 7” and a Liberation-First Design
One of the core premises of this library is that any text in one encoding can be converted to another, without having to know anything about external encodings. This is how the library achieves infinite extensibility! We start by noting that almost any encoding conversion can be done so long as there is an intermediary that exists between the source and the destination. For encoded text, this is the line between code units (code_unit for code) and code points (code_point for code).
Code units are single elements of a linear sequence of encoded information. That could be a sequence of bytes, a sequence of 16-bit numbers, and more. A sequence of code units is typically specific to the encoding it has and is generally impossible to reason about in a general or generic sense.
Code points are single elements of a linear sequence of information that have been decoded. They are far more accessible because they are generally an agreed upon interchange point that most others can access and reason about.
We leverage that, for text, **Unicode Code Points** are an agreed upon interchange format, giving rise to this general framework for encoding and decoding text:
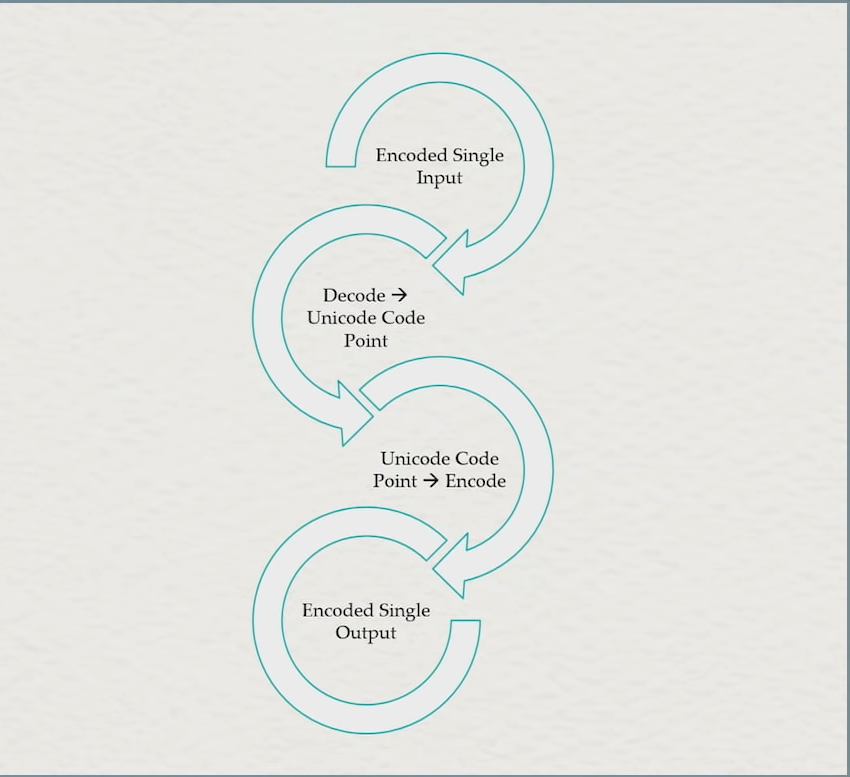
The generic pathway from one encoding to another for most (all?) text Encodings.
The way to tap into this concept is to create an object that models an encoding concept, which is commonly referred to as the “Lucky 7” concept. The concept leverages a technique that has been used at least since the early days of Bruno Haibile’s and Daiko Ueno’s iconv library, but formalizes it for interacting between 2 encodings.
We call this concept the Lucky 7.
Lucky 7
Lucky 7 is a conceptual idea a single encoding object is all you need to write to fulfill your end of the encoding bargain. It is called the Lucky 7 because only 7 things are required from you, as the author of the encoding object, to get started:
3 type definitions (
code_point,code_unit,state)2 static member variables (
max_code_points,max_code_units)2 functions (
encode_one,decode_one)
1#include <cstddef>
2#include <span>
3
4struct empty_struct {};
5
6struct utf_ebcdic {
7 // (1)
8 using code_unit = char;
9 // (2)
10 using code_point = char32_t;
11 // (3)
12 using state = empty_struct;
13
14 // (4)
15 static constexpr inline std::size_t max_code_points = 1;
16 // (5)
17 static constexpr inline std::size_t max_code_units = 6;
18
19 // (6)
20 ue_encode_result encode_one(
21 ztd::span<const code_point> input,
22 ztd::span<code_unit> output,
23 state& current,
24 ue_encode_error_handler error_handler
25 );
26
27 // (7)
28 ue_decode_result decode_one(
29 ztd::span<const code_unit> input,
30 ztd::span<code_point> output,
31 state& current,
32 ue_decode_error_handler error_handler
33 );
34};
There are some supporting structures here that we will explain one by one, but this is the anatomy of a simple encoding object that you and others can define to do this job. This anatomy explicitly enables some basic work:
encoding a single indivisible unit of work from code points to code units
decoding a single indivisible unit of work from code units to code points
transcoding a single indivisible unit of work from the source encoding’s code units to the destination encoding’s code code units, if they share a common code point type.
From these 3 operations above, everything else on this library can be built.
Breaking it Down
The first three typedefs are what let internal and external machinery know what kind of values you expect out of the ranges that go into the decode_one and encode_one function calls:
code_unit- the input for decoding (decode_one) operations and the output for encode operations.code_point- the input for encode operations and the output for decoding (decode_one) operations.
char is the code unit type that the ranges work with for incoming and outgoing encoded data. char32_t is the code point type that the ranges use for incoming and outgoing decoded data. Given those, that gives us the ability to define the result types we will be working with.
Result Types
Result types are specific structs in the library that mark encode and decode operations. They can be used by composing with the templated type ztd::text::decode_result and ztd::text::encode_result.
1#include <ztd/text/encode_result.hpp>
2#include <ztd/text/decode_result.hpp>
3
4using ue_decode_result = ztd::text::decode_result<
5 ztd::span<const char>,
6 ztd::span<char32_t>,
7 empty_struct
8>;
9
10using ue_encode_result = ztd::text::encode_result<
11 ztd::span<const char32_t>,
12 ztd::span<char>,
13 empty_struct
14>;
These result structures are returned from the lowest level encode and decode operations. They contain:
An
inputmember, which is the range that is passed into thedecode_oneandencode_onefunctions;An
outputmember;A
statemember, which is a reference to thestatethat was passed in to thedecode_oneorencode_onefunctions;An
error_codemember, which is an enumeration value from ztd::text::encoding_error; andAn
error_countmember, which is an unsigned integral (std::size_t) value that says whether or not the givenerror_handlerwas invoked and how many timesAn
errors_were_handled()member function, which returns a boolean value indicating whethererror_countis greater than 0.
These variables can be used to query what exactly happened during the operation (error_code and error_count), inspect any state passed into encodings (not used for an encoding such as utf_ebcdic), and how much input and output has been read/what is left (by checking the input and output ranges whose .begin() value has been incremented compared to the input values). Understanding the result types now, we move to the error handler:
Error Handlers
The only other thing we need is the error handler, now. Generally, this is a template argument, but for the sake of illustration we use a concrete type here:
1#include <functional>
2
3using ue_decode_error_handler = std::function<
4 ue_decode_result(
5 const utf_ebcdic&,
6 ue_decode_result,
7 ztd::span<char>,
8 ztd::span<char32_t>
9 )
10>;
11
12using ue_encode_error_handler = std::function<
13 ue_encode_result(
14 const utf_ebcdic&,
15 ue_encode_result,
16 ztd::span<char32_t>,
17 ztd::span<char>
18 )
19>;
The error handlers use a result-in, result-out design. The parameters given are:
The encoding which triggered the error. This allows you to access any information about the encoding object type or any values stored on the encoding object itself.
The result object. This object has the
error_codemember set to what went wrong (see ztd::text::encoding_error), and any other changes made to theinputoroutputduring the operation.A contiguous range (
ztd::span) ofcode_units orcode_points that were already read by the algorithm. This is useful for when theinputrange uses input iterators, which sometimes cannot be “rolled back” after something is read (e.g., consider std::istream_iterator).A contiguous range (
ztd::span) ofcode_units orcode_points that were already read by the algorithm. This is useful for when theoutputrange uses output iterators, which sometimes cannot be “rolled back” after something is written (e.g., consider std::ostream_iterator).
It returns the same type as the result object. Within this function, anyone can perform any modifications they like to the type, before returning it. This is an incredibly useful behavior that comes in handy for defining custom error handling behaviors, as shown in the Error Handling Design section. For example, this allows us to do things like insert REPLACEMENT_CHARACTER \uFFFD (�) into a encoding through the ztd::text::replacement_handler_t or enable speedy encoding for pre-validated text using ztd::text::assume_valid_handler. When writing your encode_one or decode_one function, it is your responsibility to invoke the error handler (or not, depending on the value of ztd::text::is_ignorable_error_handler).
Liberation Achieved
If you achieve all these things, then we can guarantee that you can implement all of the desired functionality of an encoding library. This is the core design that underpins this whole library, and how it frees both Library Developers from needing to manically provide every possible encoding to end-users, and end-users from having to beg library developers to add support for a particular encoding.

There is more depth one can add to an encoding object, but this is the base, required set of things to know and handle when it comes to working with ztd.text. You can build quite a complex set of features from this functionality, and we encourage you to keep reading through more of the design documentation to get an understanding for how this works!