Encode
Encoding is the action of converting from one sequence of decoded information to a sequence of encoded information. The formula given for Encoding is effectively just the first half of the diagram shown in the main Lucky 7 documentation, reproduced here with emphasis added:
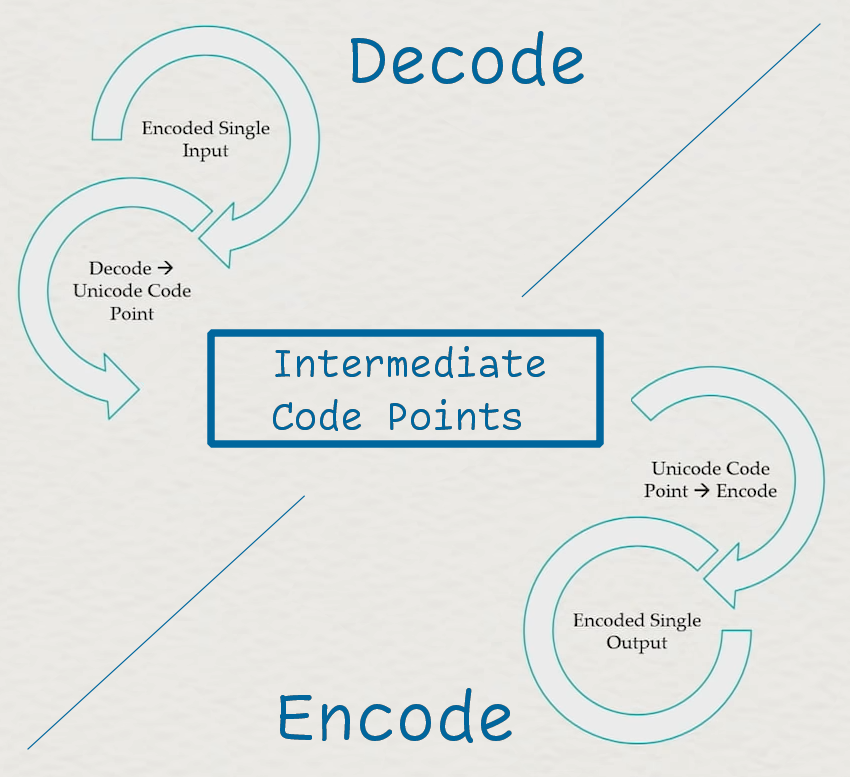
The generic pathway between 2 encodings, but modified to show the exact difference between the encoding step and the decoding step.
In particular, we are interested in the operation that helps us go from the decoded input to the encoded output, which is the bottom half of the diagram. The input in this case is labeled “intermediate”, because that is often what it is. But, there are many uses for working directly with the encoded data. A lot of the world does not speak directly in 21-bit Unicode Code Points, but instead speaks in UTF-8. Legacy systems are often found communicating with Code Pages (e.g., EBCDIC or SHIFT-JIS); until those systems go down or are replaced, it is imperative to send them well-formed data, whether over a network or across an inter-process communication bridge of any kind.
Thusly, we use the algorithm as below to do the work. Given an input of code_points with an encoding, a target output, and any necessary additional state, we can generically convert that sequence of code_points into its encoded form:
⏩ Is the
inputvalue empty? If so, is thestatefinished and have nothing to output? If both are true, return the current results with the the emptyinput,output, andstate, everything is okay ✅!⏩ Otherwise,
Do the
encode_onestep frominput(using itsbegin()andend()) into theoutputcode_unitstorage location.🛑 If it failed, return with the current
input(unmodified from before this iteration, if possible),output, andstates.
⏩ Update
input‘sbegin()value to point to after what was read by theencode_onestep.⤴️ Go back to the start.
This involves a single encoding type, and so does not need any cooperation to go from the code_point sequence to the code_unit sequence.
Check out the API documentation for ztd::text::encode to learn more.