Transcode
Transcoding is the action of converting from one sequence of encoded information to another sequence of (usually differently) encoded information. The formula given for Transcoding is actually exactly the same as the one shown in the main Lucky 7 documentation, reproduced here:
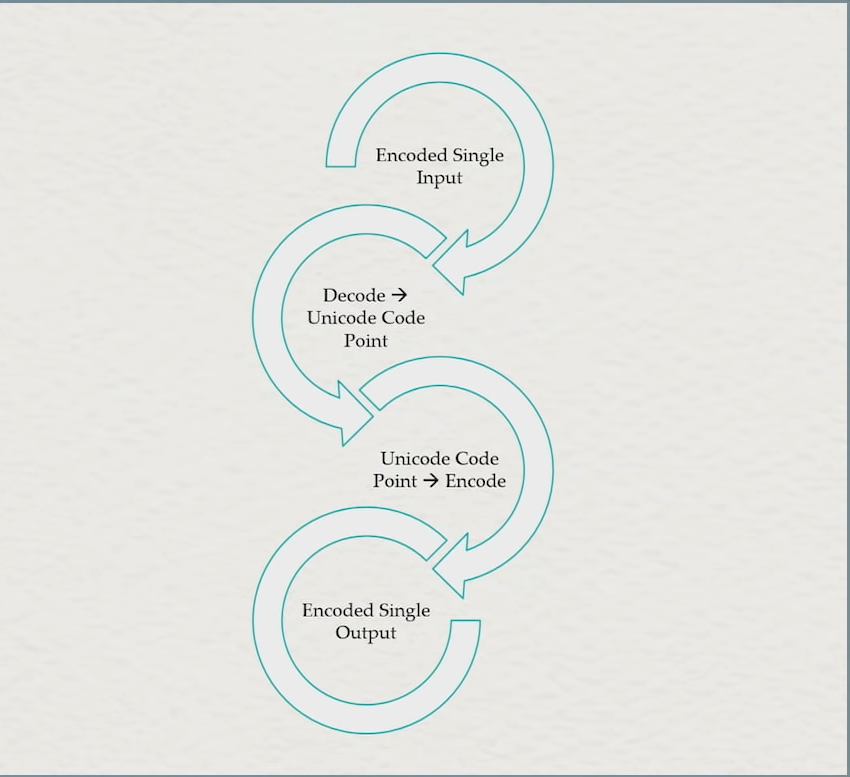
The generic pathway from one encoding to another for all text Encodings.
The core tenant here is that as long as there is a common intermediary between the 2 encodings, you can decode from the given input into that shared common intermediary (e.g., unicode code points or unicode scalar values), then encode from the common intermediary to the second encoding’s output. This is a pretty basic way of translating data and it’s not even a particularly new idea (iconv has been doing this for well over a decade now, libogonek got this core idea rolling in a C++ interface, and in general this is quite literally how all data interchange has been done since forever). The equalizer here is that, unlike other industries that struggle to define an interchange format, Unicode Code Points has become the clear and overwhelming interoperation choice for people handling text all over the world.
Thusly, we use the algorithm as below to do the work. Given an input of code_units with a from_encoding, a to_encoding with a target output, and any necessary additional states, we can generically convert that one encoding to the other so long as those encodings follow the Lucky 7 design:
⏩ Is the
inputvalue empty? If so, is thestatefinished and have nothing to output? If both are true, return the current results with the the emptyinput,output, andstate, everything is okay ✅!⏩ Otherwise,
Set up an
intermediatestorage location ofcode_points, using themax_code_pointsof the input encoding as the maximum size of the storage location, for the next operation.Do the
decode_onestep frominput(using itsbegin()andend()) into theintermediatecode_pointstorage location.🛑 If it failed, return with the current
input(unmodified from before this iteration, if possible),output, andstates.
Do the
encode_onestep from theintermediateinto theoutput.🛑 If it failed, return with the current
input(unmodified from before this iteration, if possible),output, andstates.
⏩ Update
input‘sbegin()value to point to after what was read by thedecode_onestep.⤴️ Go back to the start.
This fundamental process works for any 2 encoding pairs, and does not require the first encoding from_encoding to know any details about the second encoding to_encoding! This means a user is only responsible for upholding their end of the bargain with their encoding object, and can thusly interoperate with every other encoding that speaks in the same intermediate, decoded values (i.e. unicode code points).
Check out the API documentation for ztd::text::transcode to learn more.